K-Means Clustering
Have your software detect clusters
You would expect that problems that are easily solved by man, are also easily solved by machines, but in many cases (or most cases?) they are not. One of those problems is pattern detection.
I ran into one of these problems the other day. In groups of objects, I had to detect clusters of objects with similar (but not exactly the same) properties.
K-Means
While I was looking for techniques that could help me in finding these clusters of similar things that would assist me in finding the title, I came across K-Means. I had seen it getting mentioned a couple of times in the context of Hadoop, but in my case, I certainly couldn't afford to turn it into a Hadoop job.
Yet I wanted to be able to play around with K-Means for a while, just to be sure I understood how it could help me. So I dug around for a Java/Scala implementation for a while, but as I couldn't find any, I eventually decided to write my own.
K-Means in Scala
So I wrote it in Scala, my favorite language of the whole world. Now, I actually found it pretty hard to find out how technique supposed to work. It is documented on Wikipedia, but it includes a lot of mathematical notation, which doesn't help the layman - which I have become, 20-something years after I studied math.
1-minute user guide
This is how it works. Suppose you have a list of tuples, with every tuple consisting of two double values. You can think of them as coordinates of things in a two-dimensional coordinate system. If you want to partition that collection of tuples into two clusters, then this is how you do that:
val points = List(
(1.0, 1.0),
(1.5, 2.0),
(3.0, 4.0),
(5.0, 7.0),
(3.5, 5.0),
(4.5, 5.0),
(3.5, 4.5)
)
cluster(points, 2)
... which results in this:
List(
List((1.0,1.0), (1.5,2.0)),
List((3.0,4.0), (5.0,7.0), (3.5,5.0), (4.5,5.0), (3.5,4.5))
)
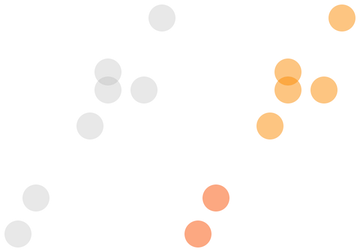
As you can see, it partitioned the collection into two separate collections based on how far they are apart. So we basically went from a unpartitioned collection of points as the one with grey dots below, to a partitioning of that collection as illustrated by the figure right next to it.
Tuples only?
Unfortunately, not everything in life is a tuple, and nothing all object properties are in themselves coordinates on an axis of a multidimensional vector space. Ideally, the API would accommodate for that.
In order to apply K-means, you need to be able to map objects to things for which you can 1) measure the distance between them, and 2) calculate the centroid (the center of mass). I borrowed an idea from textgrounder to define these two properties as a trait:
trait VectorSpace[A] {
def distance(x: A, y: A): Double
def centroid(ps: Seq[A]): A
}
The cluster operation takes an instance of this trait as an implicit parameter. This allows me to apply K-means to anything for which I have a corresponding vector space. (The main benefit of this is that in some cases, distance isn't the shortest line between two points, as in - for instance - the distance between two cities on the earth.)
The example given above is using is interpreting the objects getting passed in as points in a two dimensional space, and is calculating the distance and centroid as you would expect.
type Point = (Double, Double)
implicit object EuclidianVectorSpace {
def distance(x: Point, y: Point): Double =
sqrt(pow(x._1 - y._1, 2) + pow(x._2 - y._2, 2))
def centroid(ps: Seq[Point]): Point = {
def pointPlus(x: Point, y: Point) = (x._1 + y._1, x._2 + y._2)
ps.reduceLeft(pointPlus) match {
case (a, b) => (a / ps.size, b / ps.size)
}
}
}
}
As you can see, it expects objects to be of type Point, which is simply a type alias for a Tuple of two Doubles. Now, as I said, objects are not always Tuples of Doubles. So you need to need a way to transform the objects you want to cluster into objects understood by the VectorSpace instance. That's the second implicit argument passed to cluster:
def cluster[T,U](xs: Seq[T], k: Int)
(implicit projection: T => U, space: VectorSpace[U]): Seq[Seq[T]]
That function mapping objects from your collection to objects understood by the cluster operation is one for which you might have multiple versions. Having that getting passed in as an implicit argument in all circumstances might be a bit awkward. That's why I also added a second version of cluster, that takes that function as a first argument:
def cluster[T,U](fn: T => U)(xs: Seq[T], k: Int)
(implicit g: VectorSpace[U]): Seq[Seq[T]] = cluster(xs, k)(fn,g)
Now I can call cluster on any collection of objects, provided that there is a function that maps the object to an object defined by an instance of VectorSpace made available explicitly:
case class Coordinate(x: Double, y: Double)
val points = List(
Coordinate(1.0, 1.0),
Coordinate(1.5, 2.0),
Coordinate(3.0, 4.0),
Coordinate(5.0, 7.0),
Coordinate(3.5, 5.0),
Coordinate(4.5, 5.0),
Coordinate(3.5, 4.5)
)
def coordinateToPoint(coordinate: Coordinate) = (coordinate.x, coordinate.y)
val clustered = cluster(coordinateToPoint)(points, 2)
Happy?
I'm not happy with the API yet. Although the textgrounder idea of factoring out - what they call - the Geometry seems great at first, I get the impression that for all practical purposes, the only thing you really want to vary is the number of dimensions, not necessarily the way you calculate distance and the centroid.
Implementation
Even though I share some abstractions with textgrounder, the implememtation is totally different. Textgrounder uses an implementation that has mutable state; in other words, they use vars to keep track of state between different iterations of the iterative algorithm. In my case, I use recursion: everything is immutable, which potentially makes it easier to run parts of it in parallel:
def cluster[T,U](xs: Seq[T], k: Int)
(implicit projection: T => U, space: VectorSpace[U]): Seq[Seq[T]] = {
case class Pair(original: T) {
val projected = projection(original)
}
@tailrec
def step(xs: Seq[Pair], centroids: Seq[U]): Seq[Seq[Pair]] = {
val labeled =
for (x <- xs) yield {
val distances =
for ((centroid) <- centroids)
yield (centroid, space.distance(x.projected, centroid))
val nearestCentroid = distances.minBy(_._2)._1
(nearestCentroid, x)
}
val grouped = for (centroid <- centroids) yield labeled.collect({
case (`centroid`, x) => x
})
val replacements =
grouped.map(group => space.centroid(group.map(_.projected)))
val stable =
replacements.forall {
replacement =>
centroids.exists(centroid => centroid == replacement)
}
if (stable) {
grouped
} else {
step(xs, replacements)
}
}
val associated = xs.map(Pair)
val initial = pickRandom(associated.map(_.projected), k)
step(associated, initial).map(_.map(_.original))
}
You can find the sources here, on Github.